
VMware for Beginners – Overview of vSphere: Part 1
VMware for Beginners – vSphere Installation Requirements: Part 2
VMware for Beginners – How to Install vSphere: Part 3
Read More
The last VMware for Beginners article, we discuss about VMware vSphere HA and publish the first part out of three of this subject. This is the second part.
vSphere HA is an essential component of the vSphere platform that provides cost-effective high availability for mission-critical workloads.In this second part, we will discuss how to configure vSphere HA
What will we learn in this vSphere HA topic?
- How to configure vSphere HA
- Detailed each vSphere HA and explained how It works
To start and enable vSphere High Availability, go to vCenter – Cluster – Configure – vSphere Availability and click Edit, then enable vSphere HA.

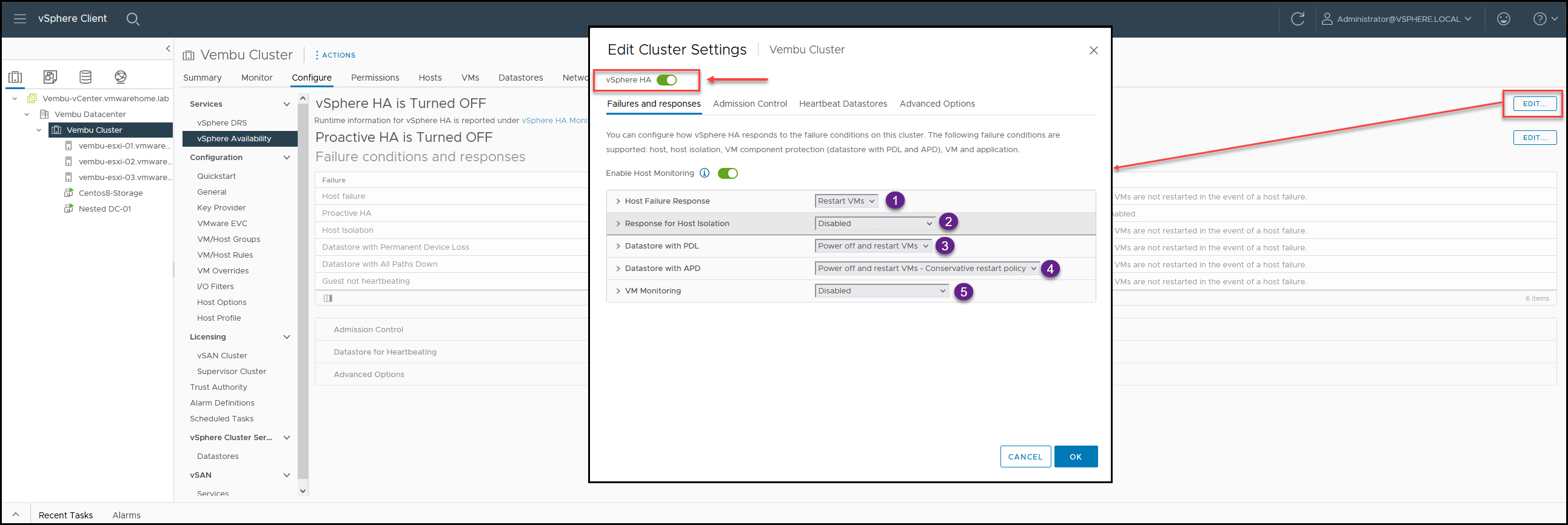
Let us go through all the options we have when configuring vSphere HA.
In the tab Failures and responses:
1. Host Failure Response
This option is what vSphere HA will do when a host fails, types of failures are listed below:
You only have two options for what to do when a Host fails.
- Disabled
Host Monitoring is turned off. vCenter will not respond to host failures.
- Restart VMs
VMs will be restarted in the order determined by their restart priority when a Host failure is detected.
If we want a vSphere HA, we should enable and select Restart VMs.
2. Response for Host Isolation
In this case, if we have an isolated host, what should vSphere HA do?
There will be three options as listed below:
- Disabled
No action would be taken on the affected VMs.
- Power off and restart VMs
All affected VMs will be turned off, and vSphere HA will attempt to restart the VMs on hosts that has network connectivity.
- Shut down and restart VMs
All affected VMs will be gracefully shutdown, and vSphere HA will attempt to restart the VMs on hosts that are still online.
Shutdown and restarting VMs is the default option and the best practices. vSphere HA tries to power off gracefully all the VMs and power them on in the next available ESXi host.
This is important if you have applications on your VMs that could be corrupt with a hard restart. So trying to gracefully shutdown is essential.
Note: Gracefully shutdown only works if you have VMware Tools installed in your VM. If not, vSphere HA will power off the VM and restart VM in the next available ESX host.
3. Datastore with PDL (Permanent Device Loss)
A Datastore with PDL is when, the following cases occur:
- The Storage view displays a datastore as unavailable
- The operational state of the device is listed as Lost Communication by a storage adapter
- The device is designated as Dead along every path
In this case, a Host has a Permanent Device Loss where VMs are running, and vSphere HA needs to address the problem since VMs are running on the Datastore.
Note: This will only address a Host problem that cannot connect to the Datastore.
Here we also have three options, disable, only log the events, or Power off and restart VMs. By default is the last option and the Best Practice.
- Disabled
No action will be taken to the affected VMs.
- Issue events
No action will be taken to the affected VMs; events will be generated.
- Power off and restart VMs
All affected VMs will be terminated and vSphere HA will attempt to restart the VMs on hosts that has connectivity to the datastore.
4. Datastore with APD (All-Paths-Down)
A Datastore with APD is when:
- A datastore is shown as unavailable in the Storage view
- A storage adapter indicates the Operational State of the device as Dead or Error
- All paths to the device are marked as Dead
- You are unable to connect directly to the ESXi host using the vSphere Client
- The ESXi host shows as Disconnected in vCenter Server
This is one of the most severe issues that we can have in our Cluster with our ESXi hosts. All VMs will be unavailable, mainly if this happens in more than one ESXi host(depending on how many Host failures your Cluster tolerates), the Cluster can be unavailable or ESXi hosts can be unstable.
There are four options on how vSphere HA handles an APD.
I do not recommend the first and second since an APD can be a considerable issue in your environment, so you have more conservative or aggressive options.
It all depends on how you want to configure your environment, and SLAs are very important to take into account(again, any VMs with critical Applications restarts and Power on in the next ESXi host available) since an aggressive policy restarts the VM as long there is no connection.
By default, vSphere HA selects the Power off and restart VMs – Conservative restart policy.
- Disabled
No action taken on the affected VMs.
- Issue events
No action taken on the affected VMs. Events will be generated.
- Power off and restart VMs – Conservative restart policy
A VM will be powered off, if the vSphere HA determines that the VM can be restarted on a different host.
- Power off and restart VMs – Aggressive restart policy
A VM will be powered off, If vSphere HA determines the VM can be restarted on a different host, or if HA cannot detect the resources on other hosts because of network connectivity loss (network partition).
In the same APD option, we have a second option where we cant select the Response Recovery and Response delay for the VMs.
It is disabled by default, but you can set 2/3m (example). Which is the number of minutes that VMCP (VM Component Protection ) waits before taking action.
VSphere HA waits that time and waits for Cluster and ESXi hosts to recover from the APD before starting to restart VMs in another host.
Note: To enable Application Monitoring, you must first obtain the appropriate SDK (or be using an application that supports VMware Application Monitoring).
From time to time, when a virtual machine or application works as expected, it ceases to send heartbeats.
To keep unnecessary resets at bay, the VM Monitoring service also oversees a virtual machine’s I/O activity. If no heartbeats are detected within the failure interval, then the I/O stats interval (a cluster-level attribute) is consulted.
This I/O stats interval registers any disk or network activity that has taken place during the last two minutes (120 seconds). And if there is nothing to show for it, then the virtual machine gets reset. This default value (120 seconds) can be altered by employing an advanced option das.iostatsinterval.
Enable heartbeat monitoring
- Disabled
- VM Monitoring Only
Turns on VMware tools heartbeats. The VM is reset when heartbeats are not received within a set time.
- VM and Application Monitoring
Turns on application heartbeats. The VM is reset when heartbeats are not received within a set time.
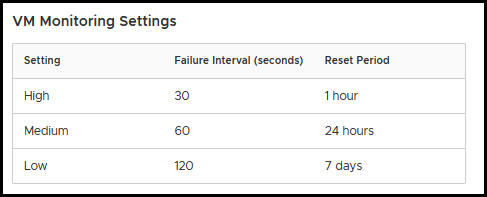
The last option in VM Monitoring is the VM monitoring sensitivity.
You can adjust the monitoring sensitivity to best suit your needs. If you choose a high level, it will enable faster detection of failures.
However, this setting has a higher risk of mistakenly concluding that a virtual machine or application has failed when it is still operational due to resource constraints.
On the contrary, selecting a lower sensitivity option will mean service interruptions between actual failures and VM resetting of VMs may last longer. Consider what option works best for you before making a selection.
You can use the vSphere HA automatically default settings or do it manually. For the auto settings, these are the defaults.
Note: The interval and reset times option is only available if you select Custom.
You can set the number of times a VM can be reset in a period of time.
When failures are detected, vSphere HA resets virtual machines to ensure services remain available. To prevent continual restarts due to persistent errors, vSphere HA has a specific setting to limit the number of resets done in a specific configurable time interval.
This setting, Maximum per-VM resets, can be configured by the user, and after three attempts, no further retries occur until the set interval has passed.
Note: The reset statistics are cleared when a virtual machine is powered off and back on or migrated using vMotion to another host. This causes the guest operating system to reboot, but it is not the same as a ‘restart’ in which the virtual machine’s power state is changed.
5. VM Monitoring
With the VM Monitoring, we finish the second part(of 3) of this VMware for Beginners – vSphere HA– Part 14. Watch out for the third (or) last part in upcoming days.VM Monitoring
Even if VM Monitoring is disabled by default, it is a significant feature to protect your Virtual Machines and have a proper High Availability.
VM monitoring resets individual VMs if they don’t receive VMware tools heartbeats within a set period of time. Application monitoring resets individual VMs if they don’t receive in-guest heartbeats within a set period of time.
As discussed above, VMware Tools must be installed in your Virtual Machines to use this feature.
It is disabled by default, and the other options are: Monitor the Virtual Machine only or monitor the Virtual Machine Application.
VMware for Beginners – vSphere Networking: Part 4
VMware for Beginners – vSphere Datastores: Part 5
VMware for Beginners – vSphere Virtual Machines: Part 6
VMware for Beginners – How to Install vCenter: Part 7
VMware for Beginners – Datacenter and Clusters: Part 8
VMware for Beginners – How to Create and Configure iSCSI Datastores: Part 9(a)
VMware for Beginners – How to Create and Configure iSCSI Datastores : Part 9(b)
VMware for Beginners – How to Create NFS Datastores: Part 10(a)
VMware for Beginners – How to Create NFS Datastores: Part 10(b)
VMware for Beginners – vMotion and DRS: Part 11
VMware for Beginners – vSphere HA Configuration: Part 12(a)
Follow our Twitter and Facebook feeds for new releases, updates, insightful posts and more.